
Part:BBa_K4712032
H5N1-F1
The primers were designed using NCBI BLAST and SanpGene to achieve efficient and specific amplification. This primer in RPA serves as the initial binding point for the amplification process, ensuring the specificity of the reaction by targeting the desired Influenza A virus(2004H5N1) DNA or RNA sequences. The primers provided data for mathematical modeling for further primer design.
Sequence and Features
- 10COMPATIBLE WITH RFC[10]
- 12COMPATIBLE WITH RFC[12]
- 21COMPATIBLE WITH RFC[21]
- 23COMPATIBLE WITH RFC[23]
- 25COMPATIBLE WITH RFC[25]
- 1000COMPATIBLE WITH RFC[1000]
Protocol Apparatus: Thermal Cycler, Centrifuge, Fluorescence Quantitative PCR Instrument (Ya Rui), 2mL reaction tube, Pipette and Pipette Tip Materials: 1. DNA Isothermal Amplification Reagent Kit (EasyGene Biotechnology) 2. ddH2O 3. Isothermal Amplification Specific Primers:
| H5N1-F1 | H5N1-R1 | H5N1-F2 | H5N1-R2 | H5N1-F3 | H5N1-R3 | H5N1-F4 | H5N1-R4 |
|---|---|---|---|---|---|---|---|
| H5N6-F1 | H5N6-R1 | H5N6-F2 | H5N6-R2 | H5N6-F3 | H5N6-R3 | H5N6-F4 | H5N6-R4 |
| Mtu-F1 | Mtu-R1 | Mtu-F2 | Mtu-R2 | Mtu-F3 | Mtu-R3 | Mtu-F4 | Mtu-R4 |
| NME-F1 | NME-R1 | NME-F2 | NME-R2 | NME-F3 | NME-R3 | NME-F4 | NME-R4 |
| SARS-CoV-F1 | SARS-CoV-R1 | SARS-CoV-F2 | SARS-CoV-R2 | SARS-CoV-F3 | SARS-CoV-R3 | SARS-CoV-F4 | SARS-CoV-R4 |
| SARS-CoV-F5 | SARS-CoV-R5 | SARS-CoV-F6 | SARS-CoV-R6 | SARS-CoV-F7 | SARS-CoV-R7 | SARS-CoV-F8 | SARS-CoV-R8 |
| Cd-F1 | Cd-R1 | Cd-F2 | Cd-R2 | Cd-F3 | Cd-R3 | ||
| SP-F1 | SP-R1 | SP-F2 | SP-R2 | SP-F3 | SP-R3 | SP-F4 | SP-R4 |
| HAdV-B-F1 | HAdV-B-R1 | HAdV-B-F2 | HAdV-B-R2 | HAdV-B-F3 | HAdV-B-R3 | HAdV-B-F4 | HAdV-B-R4 |
| HAdV-C-F1 | HAdV-C-R1 | HAdV-C-F2 | HAdV-C-R2 | HAdV-C-F3 | HAdV-C-R3 |
4. DL500 marker 5. Test Sample: DNA Template(pUC57-M1)Concentration:1000cps/μL Storage: -20℃ Methods: 1. For a 20μL reaction system:
| Reagent | Stock Concentration | Volume Added(μL) |
|---|---|---|
| Forward Primer | 10μM | 1 |
| Reverse Primer | 10μM | 1 |
| Rehydration Buffer (2X) | 10 | |
| DNA Template | 10nM/L | 2 |
| ddH2O | To 18 | |
| Starter (10X) | 2 |
2. Gently tap to mix several times, briefly centrifuge, repeat 3 times (mix gently to avoid vigorous vortexing). 3. Incubate at 37°C for 20 minutes. 4. After heating at 65°C for 10 minutes, proceed to gel electrophoresis.Apparatus: Thermal Cycler, Centrifuge, Fluorescence Quantitative PCR Instrument (Ya Rui), 2mL reaction tube, Pipette and Pipette Tip Result

Electrophoresis of RPA Primer Screening for Influenza A H5N1 gene

 (a)
(a)

Figure 10. Linear graphs and figures (a) correspond to the fluorescence intensity of crRNAs targeting H5N1 after one-tube reaction of RPA and CRISPR under Bright and UV illumination. No crRNA is added into negative control. The concentration of DNA template is 10nM/L.
Machine Learning
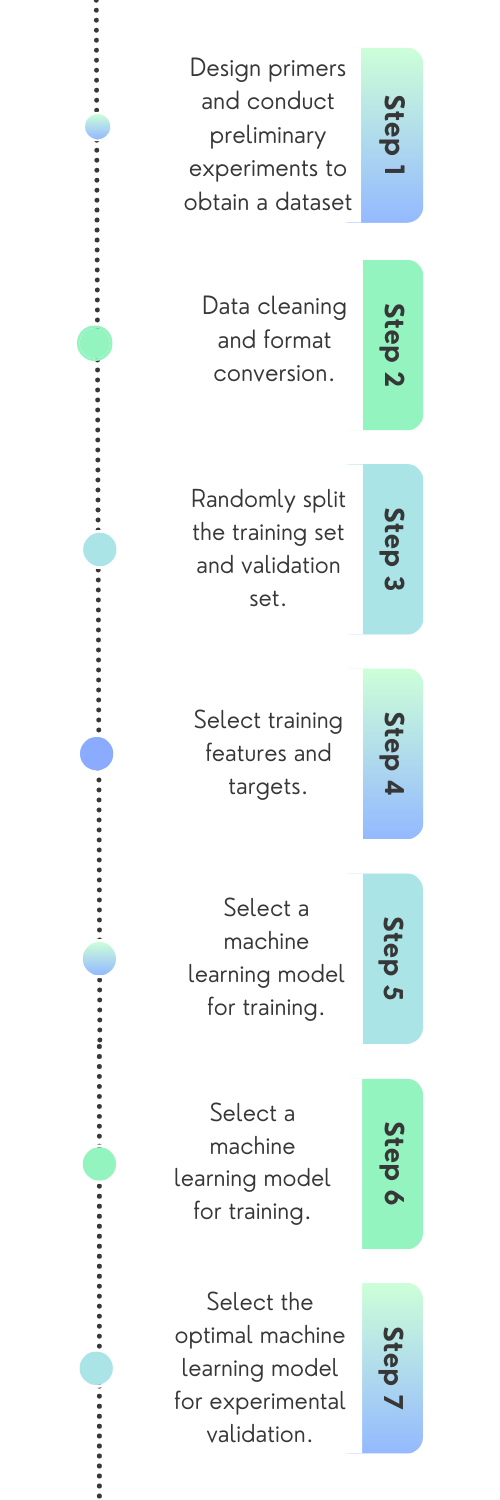
In the initial phase, we trained the model with a limited dataset of 74 data points, followed by an evaluation that proved that the support vector machine model fits into the evaluation.
Subsequently, during the second round, our focus shifted to fine-tuning the SVM model parameters. Notably, this round of training also relied on the same 74 data points. It is pertinent to mention that both the first and second rounds of training and evaluation employed randomly partitioned datasets.
In the third round, our model made predictions for the performance of 40 entirely new primers, which were unlabeled. The practical utility of these predictions was validated through experimental verification, confirming the high accuracy and reliability of our model. The alignment between the predicted class and the experimental class was particularly strong.
This approach effectively underscores the potential of machine learning to reduce the number of experiments required.
Machine Learning
In the initial phase, we trained the model with a limited dataset of 74 data points, followed by an evaluation that proved that the support vector machine model fits into the evaluation.
Subsequently, during the second round, our focus shifted to fine-tuning the SVM model parameters. Notably, this round of training also relied on the same 74 data points. It is pertinent to mention that both the first and second rounds of training and evaluation employed randomly partitioned datasets.
In the third round, our model made predictions for the performance of 40 entirely new primers, which were unlabeled. The practical utility of these predictions was validated through experimental verification, confirming the high accuracy and reliability of our model. The alignment between the predicted class and the experimental class was particularly strong.
This approach effectively underscores the potential of machine learning to reduce the number of experiments required.
| None |